Overview
This system consumes data from the Twitter Streaming API, manipulates the data using a series of Heroku apps, and generates a dynamic visualization of the manipulated data.
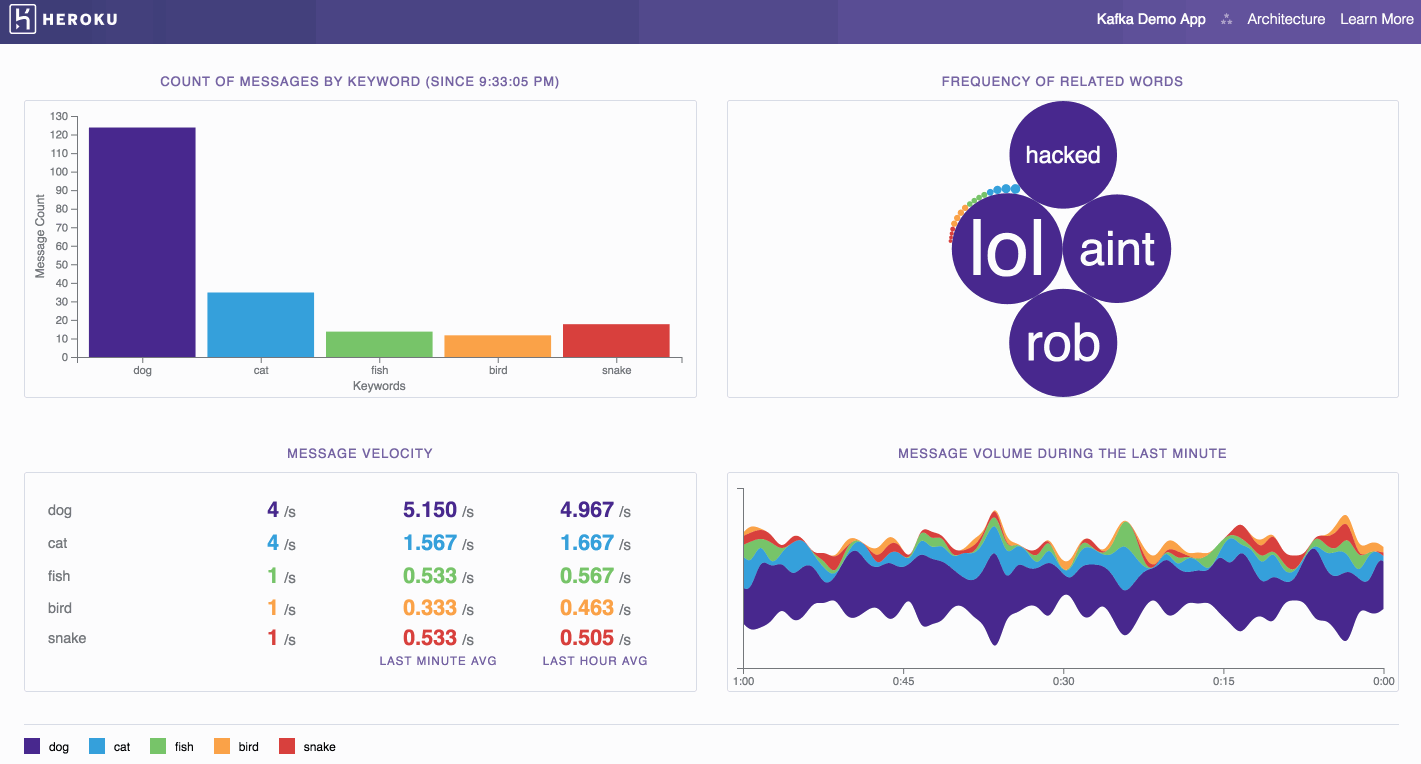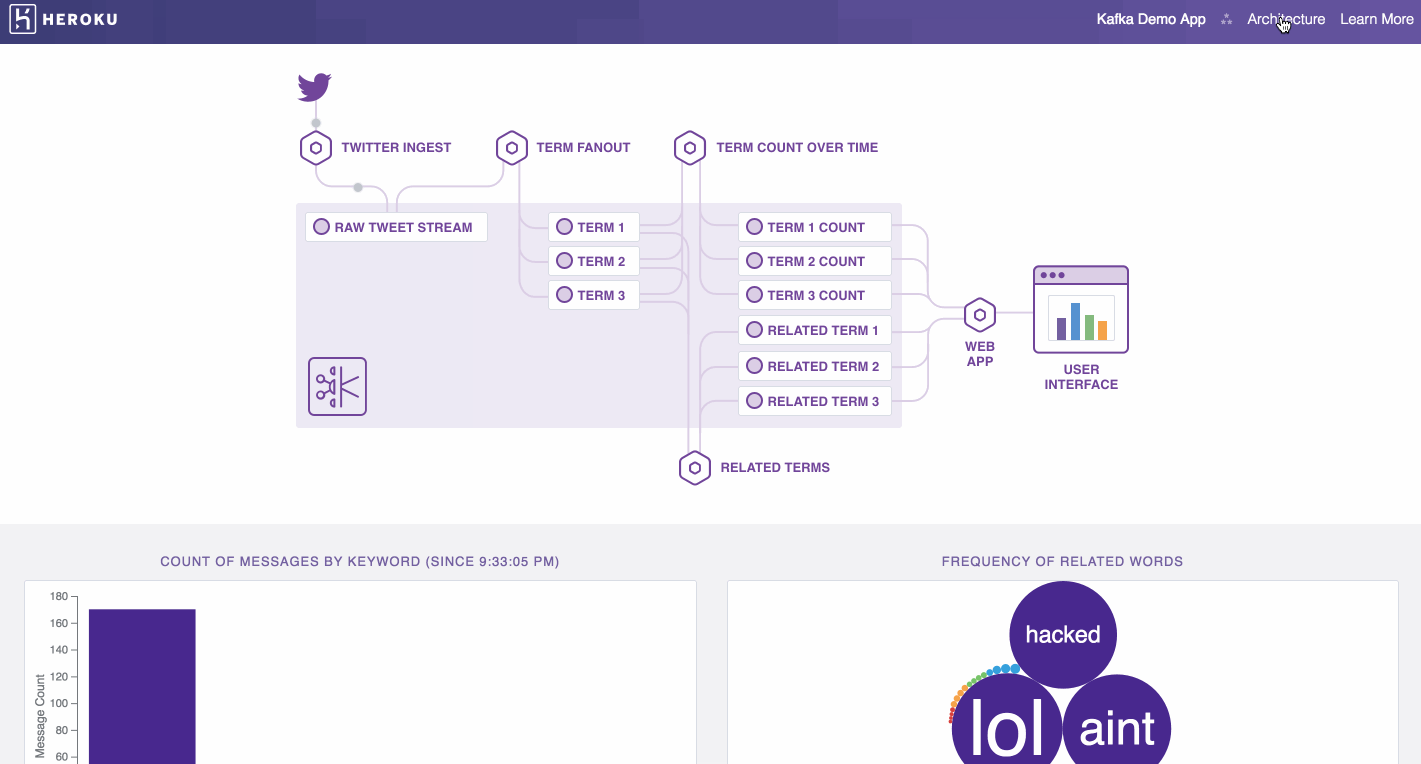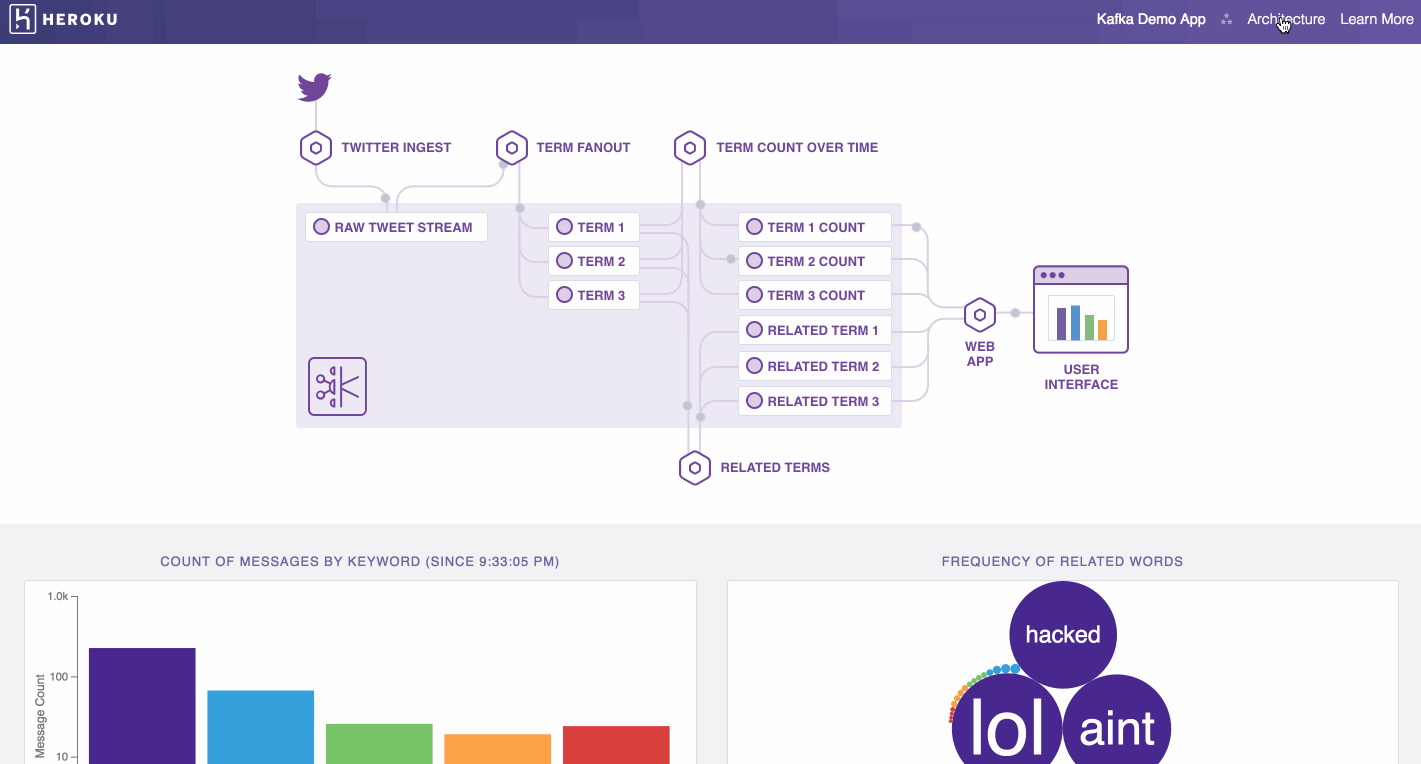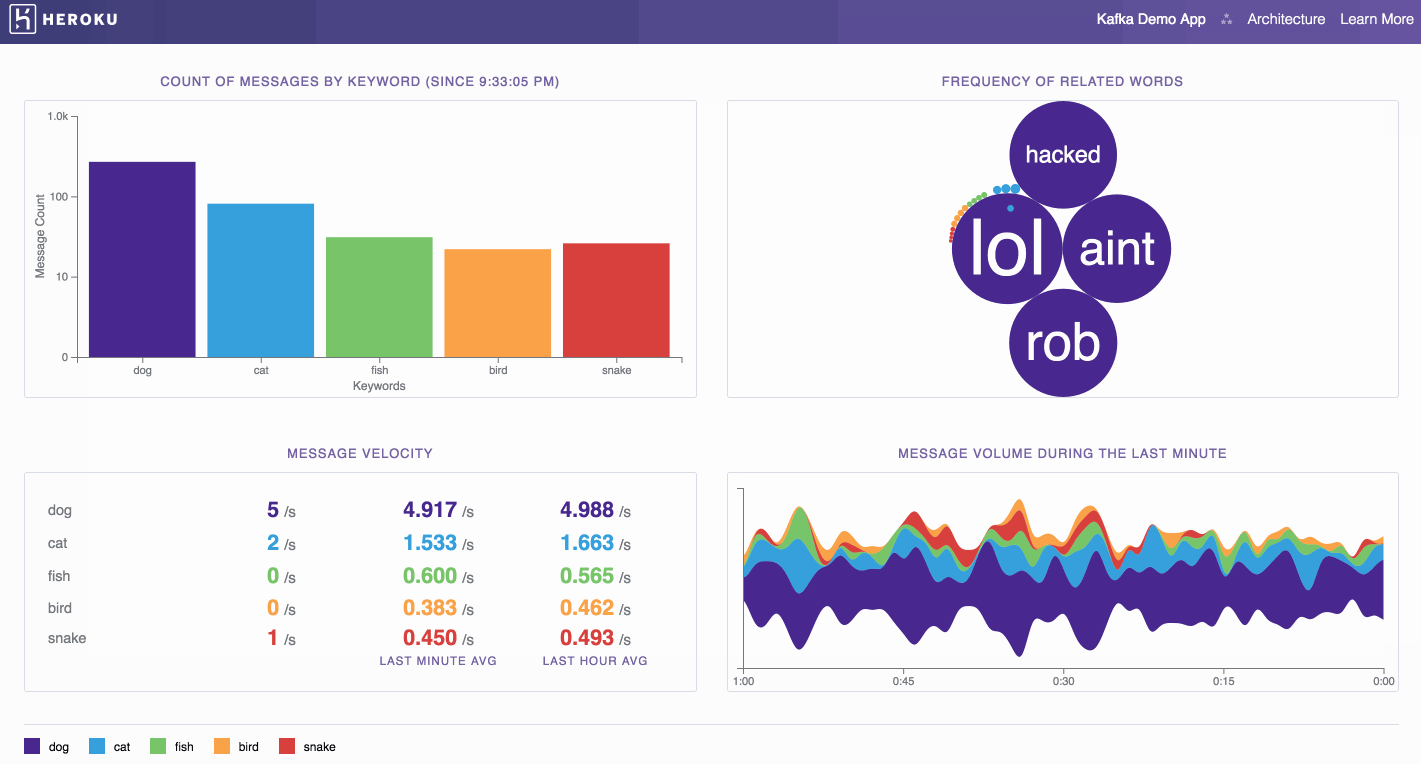
The architecture uses five Heroku apps, each serving a different role in the data pipeline.
- Data Ingest: Read from Twitter streaming API and produce messages for high volume ingest on Kafka topic
- Data Fanout: Consume ingested messages and fans out to discrete keyword Kafka topics
- Aggregate Statistic Calculation: Consume messages from keyword Kafka topics, and calculate and produce aggregate mention count to a topic
- Related Terms Generation: Consumes messages from keyword Kafka topics, and produce related words & related word count to a topic
- Visualization: Consume messages from aggregate and related words Kafka topics and generate the dynamic stream visualizations in a web application